

인터프리터와 JIT
`JavaScript`의 기본 컴파일러는 V8엔진의 `인터프리터(Interpreter)` 입니다. 인터프리터의 특징으로는 코드를 한 줄 씩읽어 내어 바이트코드로 변환한다는 것입니다. 이렇게 변환된 바이트코드를 V8 엔진의 `Just-In-Time(JIT)` 컴파일러로 한번에 컴파일을 하는 방식을 제공하고 있습니다.
인터프리터
V8 엔진은 JavaScript 코드를 처음 실행할 때, 인터프리터를 사용하여 코드를 바이트코드(Bytecode)로 변환합니다. 인터프리터는 코드를 한 줄씩 읽어서 해석하고 실행합니다. 이 과정에서 실시간으로 코드를 실행할 수 있습니다. 인터프리터는 빠른 실행 속도를 제공하지만, 최적화된 기계어 코드보다는 비교적 느린 성능을 가질 수 있습니다.
JIT 컴파일러
V8 엔진은 인터프리터를 사용하여 바이트코드를 실행하는 동안, JIT 컴파일러를 통해 프로파일링 정보를 수집합니다. JIT 컴파일러는 프로파일링 정보를 기반으로 코드를 동적으로 컴파일하여 최적화된 기계어 코드로 변환합니다. 이 최적화된 코드는 인터프리터로 실행될 때보다 훨씬 빠른 실행 속도를 제공합니다. JIT 컴파일러를 통해 동적인 최적화가 가능하므로, 반복적으로 실행되는 코드에 대해서는 높은 성능을 보장할 수 있습니다.
`Node.js`가 이러한 방식을 통해 데이터를 처리하는 이유로는 단일 스레드 이기 때문입니다. `Node.js`에서는 이러한 단일 스레드를 사용하는 근본적인 이유로는 비동기(asynchronous) 및 이벤트 기반(event-driven)의 특성을 가지고 있기 때문입니다.
V8 Engine 메모리 구조
`Java`를 먼저 공부를 하고 보는 메모리 구조라서 그런지 `JVM(Java Vertual Machine)`과 매우 유사한 구조를 가지고 있습니다. `JVM`은 `Method Area`, `Heap`, `Stack` 3가지 영역으로 나뉘지만, `V8`은 `Heap`과 `Stack` 영역으로 나뉘어져 있습니다.
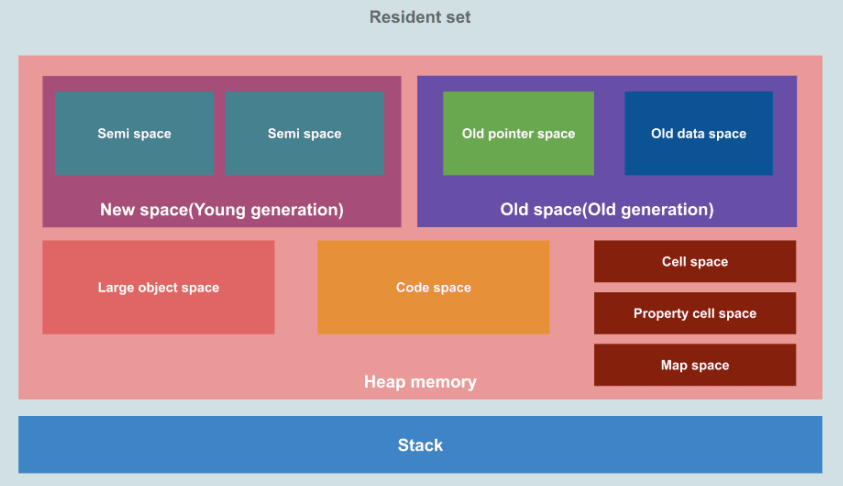
`Heap` 영역의 경우 변수가 선언이 되거나 객체가 생성되면 할당이 되는 메모리 영역으로 사용이 되지 않는 메모리 들은 `Garbage Collector`에 의해서 자동적으로 메모리에서 삭제가 됩니다. 해당 내용에 대한 자세한 부분들은 추가적으로 공부해보시는 것을 추천합니다.
`Stack` 영역의 경우, 컴파일러로 코드를 읽게 되면서 수행되는 작업들이 쌓이는 영역으로 쓰레드의 작업 공간으로 보시면 되겠습니다.
Background
`Node.js`에서 `백그라운드(Background)`는 주 스레드와 별도로 동작하는 비동기 작업을 수행하는 환경을 의미합니다. 이를 통해 오래 걸리는 작업이나 I/O 작업을 블로킹하지 않고 비동기적으로 처리할 수 있습니다. `Node.js`의 백그라운드에서는 다음과 같은 작업을 수행할 수 있습니다.
타이머 관리:
`setTimeout()`, `setInterval()`과 같은 타이머 함수를 통해 지정된 시간 후에 콜백 함수를 실행합니다. 이러한 타이머 함수는 백그라운드에서 작동하여 주 스레드를 차단하지 않고 비동기적으로 실행됩니다.
I/O 작업:
파일 시스템 액세스, 네트워크 요청, 데이터베이스 쿼리 등과 같은 I/O 작업은 주로 비동기적으로 처리됩니다. 이러한 I/O 작업은 백그라운드에서 실행되고, 작업이 완료되면 콜백 함수나 `Promise`를 통해 결과를 처리합니다.
이벤트 처리:
이벤트 기반 모델에서 백그라운드는 이벤트 루프를 통해 이벤트를 처리합니다. 이벤트는 비동기 작업의 완료, 타이머의 만료, 네트워크 요청의 응답 등을 나타낼 수 있으며, 해당 이벤트에 등록된 콜백 함수가 백그라운드에서 실행됩니다.
백그라운드에서 실행되는 작업은 주 스레드와 별개로 동작하기 때문에, 오래 걸리는 작업이나 블로킹 작업이 발생해도 주 스레드는 차단되지 않고 다른 작업을 처리할 수 있습니다. 이를 통해 `Node.js`는 비동기성과 확장성을 확보하며, 높은 처리량과 효율성을 제공합니다.
Callback 및 Callback Queue
`Callback`은 `JavaScript`에서 비동기 작업을 처리하고 결과를 다룰 때 사용되는 함수입니다. 비동기 작업이 완료되면, 해당 작업의 결과나 상태를 전달하기 위해 콜백 함수가 호출됩니다. 이렇게 콜백 함수를 등록하여 비동기 작업이 완료될 때 실행되도록 하는 것을 "콜백 패턴"이라고 합니다.
`Callback Queue`(또는 `Task Queue` 또는 `Message Queue`)는 `JavaScript `엔진이 비동기 작업의 콜백 함수를 관리하는 대기열입니다. 비동기 작업이 완료되면 해당 콜백 함수는 `Callback Queue`에 추가됩니다. 즉, 비동기 작업의 결과가 준비되면 해당 콜백 함수는 `Callback Queue`에 인큐됩니다.
`이벤트 루프(Event Loop)`는 주 스레드에서 실행되며, 주 스레드가 비어있을 때(동기적인 작업이 모두 완료되었을 때) `Callback Queue`를 확인하고 실행할 콜백 함수가 있는지 확인합니다. 이벤트 루프는 주 스레드가 비어질 때마다 `Callback Queue`를 확인하여 순차적으로 콜백 함수를 가져와 실행합니다. 이렇게 콜백 함수를 처리하는 것을 "이벤트 루프의 한 사이클"이라고 합니다.
이벤트 루프는 다음과 같은 과정을 반복하면서 비동기 작업의 콜백 함수를 실행합니다:
- 주 스레드가 비어있는지 확인합니다.
- 주 스레드가 비어있다면 `Callback Queue`에 있는 첫 번째 콜백 함수를 가져와 실행합니다.
- 콜백 함수의 실행이 끝나면 다음 사이클을 시작합니다.
- 주 스레드가 비어있지 않다면 다른 작업을 처리합니다.
- 주 스레드가 다시 비어질 때까지 이벤트 루프를 반복합니다.
이렇게 `Callback`과 `Callback Queue`는 비동기 작업의 완료 후 실행될 함수를 관리하고, 이벤트 루프를 통해 주 스레드가 비어질 때 실행됩니다. 이를 통해 비동기 작업의 결과를 적절하게 처리하고 프로그램의 비동기 흐름을 관리할 수 있습니다.
Summary
지금까지 보았던 내용들을 하나의 그림으로 정리 해보도록 하겠습니다. 먼저 `function1`, `function2`, `function3`가 순차적으로 `stack`에 쌓여있습니다. 여기서 `function2`는 `setTimeOut`의 함수를 통해 비동기로 수행이 되어집니다.

현재 `function3`가 제일 먼저 수행이 되므로 `fuction3`는 바로 수행이 되고 그 다음 `function2`는 비동기처리가 되어지므로 `background`로 이동합니다. (해당 설명에서는 `function2` 가 `function1`보다 먼저 끝난다는 배경으로 설명드리는 내용 인 것을 참고해주시기 바랍니다. )

작업이 처리가 되고 `response`를 받은 `fuction2`는 `callback queue`로 이동이 됩니다.

위에서 설명을 하였듯이 `callback queue`에 있는 명령어들을 수행하고자 한다면 현재 `stack`에는 아무런 명령어들이 없어야 합니다. 하지만 현재 `function1`이 있는 상태로 `fuction1`이 먼저 수행이 되어지고 이후 `function2`가 수행이 되어집니다.

`callbackQueue`에 있던 명령어가 `call stack`으로 이동.

`function2` 수행

이렇게 하나의 비동기 이벤트를 처리하는 것을 이벤트 루프라고 하며, 이러한 방식을 통해 `Node.js`가 작동을 하고 있습니다. 그리고 `Callback Queue`에서도 우선순위가 존재하게 되는데 우선순위는 아래와 같습니다.
- `Microtask Queue`
- `Animation Frames`
- `Task Queue`
여기서 숫자가 낮을 수록 우선순위가 높다는 의미이며, `Task Queue`가 개발자가 작성한 코드라고 보시면 되겠습니다.
장점
지금 까지 `Node.js` 작동 원리에 대해서 알아 보았습니다. 그렇다면 이러한 방식에 대한 장점은 무엇인지 알아보겠습니다.
비동기 및 논블로킹 I/O:
`Node.js`는 비동기 I/O 작업을 강조합니다. 이는 파일 시스템 액세스, 네트워크 요청 등의 I/O 작업이 완료될 때까지 기다리지 않고 다른 작업을 수행할 수 있다는 의미입니다. 이러한 비동기 I/O 작업은 작업이 완료될 때까지 블로킹하지 않고 이벤트 기반으로 처리됩니다. 이를 통해 단일 스레드에서 많은 작업을 동시에 처리할 수 있습니다.
이벤트 루프:
`Node.js`는 이벤트 루프를 사용하여 비동기 및 이벤트 기반 작업을 처리합니다. 이벤트 루프는 이벤트 처리와 관련된 콜백 함수를 이벤트 큐에 등록하고, 이벤트가 발생하면 해당 콜백 함수를 실행합니다. 이를 통해 여러 이벤트가 동시에 처리되고, 블로킹되지 않고 작업을 진행할 수 있습니다.
스레드 간의 동기화 문제 회피:
멀티 스레드로 동작하는 경우, 여러 스레드 간에 데이터 공유 및 동기화 문제가 발생할 수 있습니다. 동기화 문제는 복잡성을 증가시키고 버그를 발생시킬 수 있습니다. `Node.js`는 이러한 동기화 문제를 피하기 위해 싱글 스레드로 동작하고, 비동기 및 이벤트 기반 모델을 사용하여 문제를 회피합니다.
확장성:
`Node.js`는 싱글 스레드로 동작하지만, 비동기 및 이벤트 기반 모델을 통해 많은 수의 동시 연결을 처리할 수 있습니다. 비동기 I/O 작업을 기다리지 않고 다른 작업을 수행할 수 있으므로, 높은 처리량과 확장성을 가질 수 있습니다. 또한, `Node.js`는 멀티 프로세싱을 통해 확장성을 높일 수도 있습니다.
따라서, `Node.js`는 비동기 및 이벤트 기반의 싱글 스레드 모델을 사용하여 효율적으로 I/O 작업을 처리하고 확장성을 확보하는데 중점을 두고 있습니다. 멀티 스레드로 동작하는 대신, 비동기 작업과 이벤트 기반 처리를 통해 높은 성능과 효율성을 달성합니다.
'Backend > Node.js' 카테고리의 다른 글
| Node.js child_process (1) | 2024.01.08 |
|---|---|
| Node.js Event Architecture (0) | 2023.12.14 |
| Node.JS) Module Caching 을 알아보자 (0) | 2023.09.14 |
| Node.js TDD 단위테스트, 통합테스트 (0) | 2023.07.14 |
| Node.js (0) | 2023.06.26 |