

표준 조인(STANDARD JOIN)
일반 집합 연산자와 SQL의 비교
| 일반 집합 연산자 | SQL문 | 설명 |
| UNION 연산 | UNION | - UNION 연산은 공통 교집합 중복을 없애도 정렬작업을 발생. - UNION ALL 연산은 공통 집합을 중복해서 보여주고 정렬 작업을 하지 않음. |
| INTERSECTION 연산 | INTERSECT | - 두 집합의 공통 집합을 추출함. |
| DIFFERENCE 연산 | EXCEPT (MINUS) | - 차집합으로 첫 번째 집합에서 두 번째 집합과의 공통 집합을 제외. - Orcale은 MINUS 용어를 사용. |
| PRODUCT 연산 | CROSS JOIN | - 곱집합으로 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합. - M * N 건의 데이터 조합이 발생 - CARTESIAN PRODUCT 라고도 표현. |
순수 관계 연산자와 SQL의 비교
| 순수 관계 연산자 | SQL문 | 설명 |
| SELECT 연산 | WHERE | SELECT 연산은 SQL 문장에서는 WHERE 절로 구현. |
| PROJECT 연산 | SELECT | PROJECT 연산은 SQL 문장에서 SELECT 절의 컬럼 선택 기능으로 구현. |
| (NATURAL) JOIN 연산 | 다양한 JOIN | WHERE 절의 INNER JOIN과 FROM 절의 NATURAL JOIN, INNER JOIN, OUTER JOIN, USING 조건절, ON 조건절로 구현. |
| DIVIDE 연산 | 현재 사용안함 | 현재 사용 되지 않음. |
조인의 형태
| 조인의 형태 | 설명 |
| INNER JOIN | JOIN 조건에서 동일한 값이 있는 행만 반환. |
| NATURAL JOIN | 두 테이블 간의 동일한 이름을 갖는 모든 컬럼들에 대해 EQUI JOIN을 수행. |
| USING 조건절 | FROM 절의 USING 조건절을 이용하면 같은 이름을 가진 컬럼 중애소 원하는 컬럼에 대해서만 선택적 EQUI JOIN 가능. |
| ON 조건절 | 컬럼 명이 다르더라도 JOIN 조건을 사용할 수 있음. |
| CROSS JOIN | 일반 집합 연산자의 PRODUCT의 개념으로 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합을 만듦. |
| OUTER JOIN | JOIN 조건에서 동일한 값이 없는 행도 반환할 때 사용. |
-- JOIN
SELECT A.EMP_NO
, A.EMP_NM
, A.ADDR
, B.DEPT_CD
, B.DEPT_NM
FROM TB_EMP A, TB_DEPT B
WHERE A.DEPT_CD = B.DEPT_CD
AND A.ADDR LIKE '%수원%'
ORDER BY A.EMP_NO
;
-- NATURAL JOIN
SELECT A.EMP_NO
, A.EMP_NM
, A.ADDR
, DEPT_CD
, B.DEPT_NM
FROM TB_EMP A NATURAL JOIN TB_DEPT B
WHERE A.ADDR LIKE '%수원%'
;
-- USING 조건절
SELECT A.EMP_NO
, A.EMP_NM
, A.ADDR
, B.DEPT_NM
, DEPT_CD
FROM TB_EMP A JOIN TB_DEPT B USING (DEPT_CD)
WHERE A.ADDR LIKE '%수원%'
;
-- ON 조건절
SELECT A.EMP_NO
, A.EMP_NM
, A.ADDR
, B.DEPT_CD
, B.DEPT_NM
FROM TB_EMP A JOIN TB_DEPT B ON (A.DEPT_CD = B.DEPT_CD)
WHERE A.ADDR LIKE '%수원%'
;
-- OUTER 조인
SELECT A.EMP_NO
, A.EMP_NM
, B.DEPT_CD
, B.DEPT_NM
FROM TB_EMP A
, TB_DEPT B
WHERE B.DEPT_CD IN ('100014', '100015', '100001')
AND A.DEPT_CD(+) = B.DEPT_CD ;
SELECT A.EMP_NO
, A.EMP_NM
, B.DEPT_CD
, B.DEPT_NM
FROM TB_EMP A
RIGHT OUTER JOIN TB_DEPT B
ON (A.DEPT_CD = B.DEPT_CD)
WHERE B.DEPT_CD IN ( '100014', '100015', '100001');특징
- NATURAL 조인은 두 테이블이 공통적으로 가지고 있는 컬럼은 자동으로 조인된다.
- NATURAL 조인에서 조인 되는 컬럼에는 ALIAS 사용시 에러가 발생함.
- NATURLA 조인에서 USING 절을 사용시 명시적으로 조인되는 컬럼을 표시 가능함.
- ON 조건절을 통한 JOIN의 경우에는 ON 절에 ALIAS를 사용해야 함.
집합 연산자
집합연산자의 종류
| 종류 | 설명 |
| UNION | 중복된 행은 한개의 행으로 출력됨. |
| UNIOL ALL | 중복된 행도 그대로 결과로 표시. |
| INTERSECT | 교집합으로 중복된 행은 하나로 표시. |
| EXCEPT | 아래의 SQL문의 집합을 뺀 결과를 표시. |
-- UNION ALL
SELECT A.EMP_NM, A.BIRTH_DE
FROM TB_EMP A
WHERE A.BIRTH_DE BETWEEN '19600101' AND '19691231'
UNION ALL
SELECT A.EMP_NM, A.BIRTH_DE
FROM TB_EMP A
WHERE A.BIRTH_DE BETWEEN '19700101' AND '197901231'
;
-- UNION
SELECT A.EMP_NM, A.BIRTH_DE
FROM TB_EMP A
WHERE A.BIRTH_DE BETWEEN '19600101' AND '19691231'
UNION
SELECT A.EMP_NM, A.BIRTH_DE
FROM TB_EMP A
WHERE A.BIRTH_DE BETWEEN '19700101' AND '197901231'
;
-- INTERSECT
SELECT A.EMP_NO, A.EMP_NM, A.ADDR, B.CERTI_CD, C.CERTI_NM
FROM TB_EMP A , TB_EMP_CERTI B, TB_CERTI C
WHERE A.EMP_NO = B.EMP_NO
AND B.CERTI_CD = C.CERTI_CD
AND C.CERTI_NM = 'SQLD'
INTERSECT
SELECT A.EMP_NO, A.EMP_NM, A.ADDR, B.CERTI_CD, C.CERTI_NM
FROM TB_EMP A , TB_EMP_CERTI B, TB_CERTI C
WHERE A.EMP_NO = B.EMP_NO
AND B.CERTI_CD = C.CERTI_CD
AND A.ADDR LIKE '%용인%'
;
-- MINUS
SELECT A.EMP_NO, A.EMP_NM, A.SEX_CD, A.DEPT_CD FROM TB_EMP A
MINUS
SELECT A.EMP_NO, A.EMP_NM, A.SEX_CD, A.DEPT_CD FROM TB_EMP A
WHERE A.DEPT_CD = '100001'
MINUS
SELECT A.EMP_NO, A.EMP_NM, A.SEX_CD, A.DEPT_CD FROM TB_EMP A
WHERE A.DEPT_CD = '100002'
MINUS
SELECT A.EMP_NO, A.EMP_NM, A.SEX_CD, A.DEPT_CD FROM TB_EMP A
WHERE A.DEPT_CD = '100003'
MINUS
SELECT A.EMP_NO, A.EMP_NM, A.SEX_CD, A.DEPT_CD FROM TB_EMP A
WHERE A.SEX_CD = '1'
계층 현 질의와 SELF 조인
계층형 질의
- 테이블에 계층 형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층 형 질의를 사용.
- 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말함.
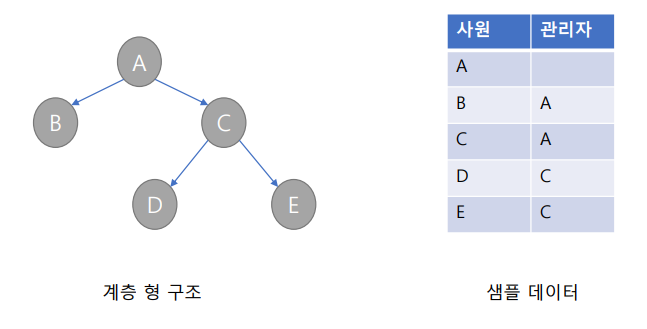
오라클 계층 형 SQL
- SELECT : 조회하고자 하는 컬럼을 지정
- FROM TABLE : 대상 테이블을 지정.
- WHERE : 모든 전개를 수행한 후, 지정된 조건을 만족하는 데이터만 추출.
- START WITH 조건 : 계층 구조 전개의 시작 위치를 지정하는 구문. 즉, 루트 데이터를 지정.
- CONNECT BY [NOCYCLE] [PRIOR] A AND B :
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문.
- PRIOR PK = FK 형태를 사용하면 계층구조에서 부모 데이터에서 자식 데이터 방행으로 전개 하는 순방향 전개.
- PRIOR FK = PK 형태를 사용하면 반대로 자식 데이터에서 부모 데이터 방향으로 전개하는 역방향 전개.
- ORDER SIBLINGS BY 컬럼 : 형제 노드 사이에서 정렬을 수행.
계층 형 질의에서 사용되는 가상 컬럼
- LEVEL : 루트 데이터는 1의 값을 가지고 하위데이터 있을 때마다 1씩 증가.
- CONNECT_BY_ISLEAF : 리프 데이터면 1 그렇지 않으면 0.
- CONNECT_BY_ROOT : 현재행 기준으로 자신의 최고 상위 ROOT를 출력함.
- SYS_CONNECT_BY_PATH : 조직인원 경로를 출력함.
SELECT LEVEL LVL
, LPAD(' ', 4*(LEVEL-1))|| EMP_NO || '(' || EMP_NM || ')' AS "조직인원"
, A.DEPT_CD
, B.DEPT_NM
, CONNECT_BY_ISLEAF
, CONNECT_BY_ROOT A.EMP_NO AS "최상위관리자"
FROM TB_EMP A, TB_DEPT B
WHERE A.DEPT_CD = B.DEPT_CD
START WITH A.DIRECT_MANAGER_EMP_NO IS NULL
CONNECT BY PRIOR A.EMP_NO = A.DIRECT_MANAGER_EMP_NO;
서브 쿼리
서브 쿼리란
- 서브 쿼리란 하나의 SQL 문안에 포함되어 있는 또 다른 SQL문.
- 서브 쿼리는 메인 쿼리의 컬럼을 모두 사용할 수 있지만 메인 쿼리는 서브 쿼리의 컬럼을 사용할 수 없다.
서브 쿼리 사용시 주의점
- 서브 쿼리를 괄호로 감싸서 사용한다.
- 서브 쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능히다.
- 단일 행 비교 연산자는 서브 쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브 쿼리의 결과 건수와 상관 없다.
- 서브 쿼리에서는 ORDER BY를 사용 하지 못한다.
서브 쿼리가 사용 가능한 위치
- SELECT절 - FROM절 - WHERE 절 - HAVING 절 - ORDER BY 절
- INSERT문의 VALUES 절 - UPDATE문의 SET 절
동작 방식에 따른 서브 쿼리 분류
- 비 연관 서브 쿼리 : 서브 쿼리가 메인 쿼리의 컬럼을 가지고 있지 않고 오로지 값을 제공하기 위한 목적으로 사용.
- 연관 서브 쿼리 : 서브 쿼리가 메인 쿼리의 값을 가지고 있는 형태.
반환 형태에 따른 서브 쿼리 분류
- 단일 행 서브 쿼리 : 실행 결과가 항상 1건 이하인 서브쿼리. 비교 연산자와 함께 사용.
- 다중 행 서브 쿼리 : 실행 결과가 여러 건인 서브쿼리. 다중 행 비교 연산자와 함께 사용.
- 다중 컬럼 서브 쿼리 : 여러 컬럼을 반환, 여러 컬럼을 동시에 비교, 메인 쿼리와 컬럼 수와 컬럼 순서가 동일 해야함.
뷰 사용의 장점
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용프로그램은 변경하지 않아도 됨.
- 편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있음.
- 보안성 : 직원의 급여 정보와 같이 숨기고 싶은 정보가 존재한다면, 뷰를 생성 할 때 해당 컬럼을 빼고 생성함.
CREATE VIEW V_TB_SAL_HIS_MAX_BY_EMP_NO
AS
SELECT A.EMP_NO, A.EMP_NM, B.DEPT_CD, B.DEPT_NM
, MAX(C.PAY_AMT) AS MAX_PAY_AMT
FROM TB_EMP A , TB_DEPT B, TB_SAL_HIS C
WHERE A.DEPT_CD = B.DEPT_CD
AND A.EMP_NO = C.EMP_NO
GROUP BY A.EMP_NO, A.EMP_NM, B.DEPT_CD, B.DEPT_NM
;
SELECT * FROM V_TB_SAL_HIS_MAX_BY_EMP_NO;
DROP VIEW V_TB_SAL_HIS_MAX_BY_EMP_NO;
그룹 함수
그룹 함수란
- 그룹 함수를 이용하여 특정 집합의 소계, 중계, 합계, 총 합계를 구할 수 있다.
그룹 함수의 종류
- ROLLUP
- 소 그룹간의 소계를 계산.
- ROLLUP 함수 내에 이낮로 지정된 GROUPING 컬럼은 SUBTOTAL을 생성하는데 사용됨.
- GROUPING 컬럼의 수가 N 이라고 했을 때 N + 1 SUBTOTAL이 생성됨.
- ROLLUP 람수 내의 인자의 순서가 바꾸면 결과도 바뀜.
- CUBE
- 다차원적인 소계를 계산하는 기능.
- 결합 가능한 모든 값에 대하여 다차원 집계 생성.
- CUBE 함수 내에 컬럼이 N 개라면 2의 N승 만큼의 SUBTOTAL 생성.
- 시스템에 많은 부담을 주기때문에 사용상 주의가 필요.
- GROUPING SETS
- 특정 항목에 대한 소계를 계산하는 기능.
윈도우 함수
윈도우 함수 개요
- 행과 행간의 관계에서 다양한 연산 처리를 할 수 있는 함수가 윈도우 함수.
- 분석함수로 알려짐.
- 윈도우 함수는 일반 함수와 달리 중첩으로 호출이 불가.
윈도우 함수의 종류
- 순위관련함수
- RANK
- DENSE_RANK
- ROW_NUMBER
- 집계관련함수
- SUM
- MAX
- MIN
- AVG
- COUNT
- 행순서관련함수
- FIRST_VALUE
- LAST_VALUE
- LAG
- LEAD
- 그룹내 비율관련함수
- CUME_DIST
- PERCENT_RANK
- NTILE
- RATIO_TO_REPORT
윈도우 함수 문법
SELECT
윈도우함수(인자) OVER (PARTITION BY 컬럼 ORDER BY 컬럼)
윈도우절(ROWS|RANGE BETWEEN UNBOUND PRECEDING|CURRENT ROW AND UNBOUNDED FOLLOWING|CURRENT ROW)
FROM 테이블명
;| 항목 | 설명 |
| 윈도우함수 | 다양한 윈도우 함수 사용 가능 |
| 인자 | 함수에 따라 0~N 개의 인자를 사용 |
| PARTITION BY | FROM절 일하에서 나온 결과 집합을 특정 컬럼을 기준으로 그룹화 가능 |
| ORDER BY | 함수 내에서 값을 정렬하는 기능. |
| 윈도우 절 | - 윈도우 함수가 연산을 처리하는 대상이 되는 행의 범위를 지정할 수 있다. - ROWS는 물리적인 결과행의 수를 뜻한다. - RANGE는 논리적인 값에 의한 범위를 뜻한다. - BETWEEN ~ AND 는 행 범위의 시작과 끝을 지정하는데 사용. - UNBOUNDED PRECEDING 은 행 범위의 시작 위치가 전체 행 범위에서 첫 번째임을 뜻함. - UNBOUNDED FOLLOWING 은 행 범위의 마지막 위치가 전체 행 범위에서 마지막 행임을 뜻함. - CURRENT ROW는 행 범위의 시작 위치가 현재 행임을 뜻함. - 1 PRECEDING은 행 범위의 시작위치가 1만큼 이전 행임을 뜻함. - 1 FOLLOWING은 행 범위의 마지막위치가 1만큼 다음 행일을 뜻함. |
SELECT A.EMP_NO, A.EMP_NM, A.BIRTH_DE, A.DEPT_CD
, (SELECT L.DEPT_NM FROM TB_DEPT L WHERE L.DEPT_CD = A.DEPT_CD) AS DEPT_NM
, RANK() OVER(ORDER BY A.BIRTH_DE) AS RANK
, DENSE_RANK() OVER(ORDER BY A.BIRTH_DE) AS DENSE_RANK
, ROW_NUMBER() OVER(ORDER BY A.BIRTH_DE) AS ROW_NUMBER
, RANK() OVER(PARTITION BY A.DEPT_CD ORDER BY A.BIRTH_DE) AS RANK_DEPT_CD
FROM TB_EMP A
WHERE A.SEX_CD = '1' --남성
ORDER BY A.BIRTH_DE;
DCL(DATA CONTROL LANGUAGE)
DCL이란?
- 유저를 생성하고 권한을 제어할 수 있는 명령어.
- 데이터의 보호와 보안을 위해서 유저와 권한을 관리 해야함.
오라클에서 제공하는 유저들
| 유저 | 설명 |
| SCOTT | 테스트용 샘플 유저 |
| SYS | DBA 권한을 부여 받은 유저 (최상위 유저) |
| SYSTEM | SYSTEM 데이터베이스의 모든 시스템 권한을 받은 유저 (SYS 바로 밑) |
-- 유저 생성
CREATE USER SQLD_TEST IDENTIFIED BY 1234;
-- 접속 권한 부여
GRANT CREATE SESSION TO SQLD_TEST;
-- TABLE 생성 권한 부여
GRANT CREATE TABLE TO SQLD_TEST;
-- DML 권한 부여
GRANT SELECT ON SQLD.TB_EMP TO SQLD_TEST;
GRANT INSERT, DELETE, UPDATE ON SQLD.TB_EMP TO SQLD_TEST;
-- 권한 회수
REVOKE CREATE TABLE FROM SQLD_TEST;
ROLE을 이용한 권한 부여
- 유저를 생성하면 많은 권한들을 부여 해야함.
- ROLE을 지정하여 포함된 권한들이 필요한 유저에게 빠르게 권한을 부여할 수 있음.
CREATE ROLE CREATE_SESSION_TABLE;
GRANT CREATE SESSION, CREATE TABLE TO CREATE_SESSION_TABLE;
GRANT CREATE_SESSION_TABLE TO SQLD_TEST;
오라클 DBMS에서 부여하는 ROLE
- CONNECT
- CREATE SESSION
- RESOURCE
- CREATE CLUSTER
- CREATE PROCEDURE
- CREATE TYPE
- CREATE SEQUENCE
- CREATE TRIGGER
- CREATE OPERATOR
- CREATE TABLE
- CREATE INDEXTYPE
절차 형 SQL
절차형 SQL 이란
- 개발언어처럼 SQL문도 절차지향적인 프로그램 작성이 가능토록 절차 형 SQL을 제공.
- SQL문의 연속적인 실행이나 조건에 따른 분기 처리를 수행하는 모듈을 생성.
- 종류로는 프로시저, 사용자정의함수, 트리거가 존재.
- 절차 형 모듈을 다른 말로 PL/SQL
PL/SQL의 개요
- PL/SQL은 BLOCK 구조로 되어 있고 BLOCK 내에는 SQL문 IF, LOOP 등이 존재.
- PL/SQL을 이용해서 다양한 모듈 개발 가능.
PL/SQL의 특징
- BLOCK 구조로 되어있으며 각 기능별로 모듈화가 가능.
- 변수/상수 선언 및 IF/LOOP문 등의 사용 가능.
- DBMS에러나 사용자 에러 정의 가능.
- PL/SQ은 오라클에 내장 시킬 수 있으며 오라클 서버간에 이식 가능.
- PL/SQL은 여러 SQL문장을 Block으로 묶고 한번에 Block전부를 서버로 보내기때문에 네트워크 패킷 수를 감소 시킴
PL/SQL 구조
- DECLARE(선언부) : BEGIN ~ END에서 사용할 변수나 인수에 대한 정의 및 데이터 타입 선언.
- BEGIN(실행 부) : 개발자가 처리하고자 하는 SQL문과 필요한 LOGIC이 정의되는 실행 부.
- EXCEPTION(예외 처리부) : BEGIN ~ END에서 실행되는 SQL문에 발생된 에러를 처리하는 부분.
- END : 함수의 끝
사용자 정의 함수
- 프로시저처럼 SQL문을 IF/LOOP등의 LOGIC과 함께 데이터베이스에 저장해 놓은 명령문의 집합.
- 함수처럼 호출해서 사용.
- 프로시저와의 차이점은 반드시 한 건을 되돌려 줘야 한다.
트리거
- DML 언어가 수행할 때 DBMS 내에서 자동으로 동작하도록 작성된 프로그램.
- DBMS가 자동적으로 수행.
프로시저와 트리거의 차이점
| 프로시저 | 트리거 |
| CREATE PROCEDURE 문법 사용 | CREATE TRIGGER 문법 사용 |
| EXECUTE/EXEC 명령어로 실행 | 생성 후 자동으로 실행 |
| 내부에서 COMMIT, ROLLBACK 가능 | 내부에서 COMMIT, ROLLBACK 실행 안됨 |
'Backend > DataBase' 카테고리의 다른 글
| MongoDB 명령어 (0) | 2023.11.15 |
|---|---|
| SQLD 최적화 (0) | 2023.11.08 |
| SQL 기본 (1) | 2023.11.07 |
| SQL vs NoSQL (1) | 2023.11.03 |
| 데이터 모델링과 성능 (1) | 2023.11.02 |